I recently needed to read a detailed summary of the first 20 or so chapters of Bleak House.
I came across this site that fit the bill perfectly.

Consistent with my habit of printing articles and reading them offline, I wanted to print these.
This posed several problems. The first is the mere fact of my having to click on each page and pressing the “Print” button over and over. The second was that for whatever reason, Firefox did not provide me with a “Reader View” option for every link. This meant the printout would look like:

Note the presence of the ad at the end and the expansive blank space near the title. That’s a lot of wasted space repeated 20 times.
Finally, given that I print 4 pages per sheet of printer paper, a lot of these summaries were too small to use up much of the paper. I would waste a lot of paper were I to go this route.
Sigh. Looks like I’ll have to find a way to scrape these. Let me reach for Scrapy.
But I really don’t want to. Scrapy is a beast and I use it so infrequently I have to relearn it every time. Could I find a better way?
Enter org-web-tools. With this package, I simply had to create an Org heading with the URLs of each link:
https://www.shmoop.com/study-guides/literature/bleak-house/summary/chapter-1 https://www.shmoop.com/study-guides/literature/bleak-house/summary/chapter-2 https://www.shmoop.com/study-guides/literature/bleak-house/summary/chapter-3 https://www.shmoop.com/study-guides/literature/bleak-house/summary/chapter-4 . . .
Thankfully, the URL scheme is sane, and Emacs macros made this a breeze.
Then I went to the heading, and entered M-x org-web-tools-convert-links-to-page-entries. It fetched all the pages, and converted them to Org mode docs.
The result:
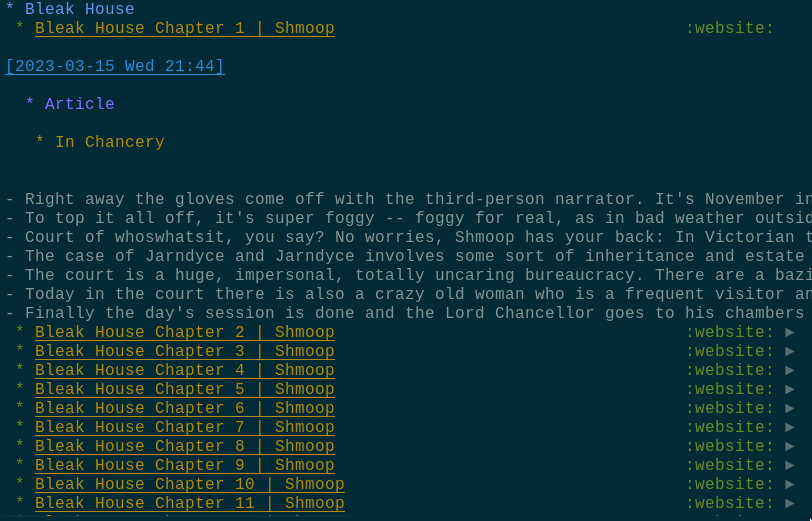
It created a node for each article, and dumped only the relevant portions into it.
I could now export this subtree to HTML, and print everything in one go. And I didn’t even need to write a scraping script! Here is what it looks like:

Comments
You can view and respond to this post in the Fediverse (e.g. Mastodon), by clicking here. Your comment will then show up here. To reply to a particular comment, click its date.